

Accéder au premier article (bases).
Commencer par un plan de gestion de données
La FAIRisation des données nécessite de prendre en compte le plus tôt possible la question de la structuration de la production et de la gestion de données, à travers la création d’un plan de gestion de données (PGD).
Le PGD décrit, entre autres, les objectifs recherchés par la collecte de données, les formats de données utilisés, le volume, les standards et les métadonnées, le type d’hébergement, les utilisateurs, la gouvernance, les mises à jour et les responsabilités. La rédaction d’un plan de gestion de données est un préalable à toute démarche FAIR.
Des données « aussi ouvertes que possible, aussi fermées que nécessaire »
Rendre les données accessibles dans le cadre de la démarche FAIR ne consiste pas à partager librement des données personnelles et confidentielles de participants ou de patients. La réglementation générale sur la protection des données personnelles (RGPD) et le code de santé publique l’interdisent formellement [1].
Ce qu’il est en revanche possible de partager librement, ce sont les informations sur les données : les métadonnées. Plus ces informations sont bien documentées, plus les données sont jugées de qualité et suscitent l’intérêt d’autres chercheurs [2] [3].
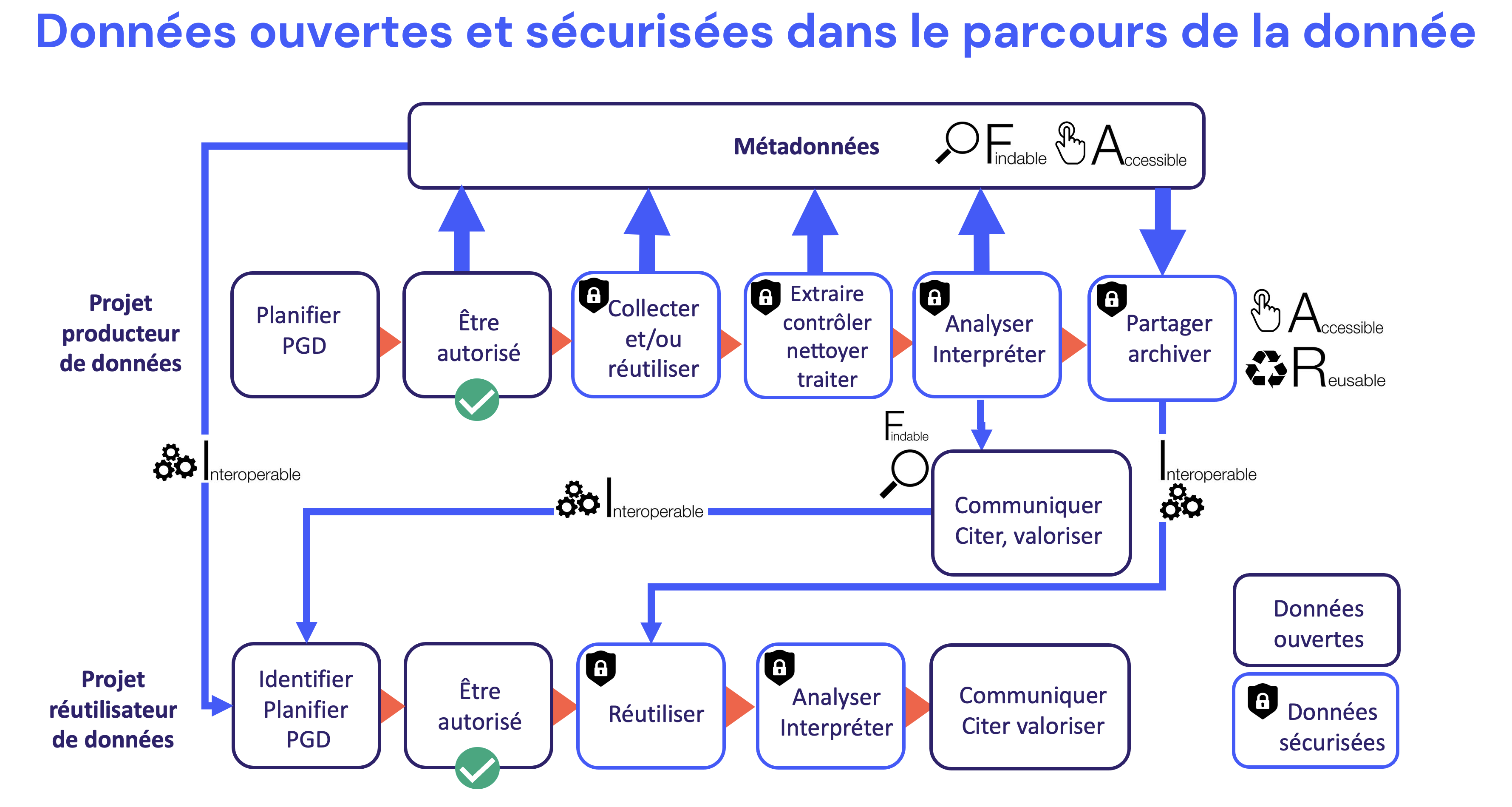
Dans tout le processus de recueil, de traitement, de partage et de réutilisation de l’information, la plus stricte confidentialité des informations est organisée de manière à ce qu’aucune donnée personnelle ne puisse être divulguée.
Deux modalités d'accès aux données
Un accès protégé pour les données identifiantes
Les chercheurs qui souhaitent accéder aux données personnelles peuvent le faire sous certaines conditions. La demande d’accès suit un enchaînement d’autorisations précis et décrit, répondant à la gouvernance des données de la cohorte et au consentement des participants [4].
Une fois ces prérequis obtenus, les données sont accessibles via un espace informatique sécurisé, conformément à la réglementation en vigueur [5].
Un accès ouvert pour les données non-identifiantes
Une mise à disposition des données de manière ouverte est possible grâce à :
leur anonymisation, effaçant toute donnée potentiellement identifiante,
ou leur transformation en jeux de données synthétiques, simulés pour produire des données présentant des caractéristiques statistiques proches, mais ne permettant pas de remonter aux personnes.
Focus : deux parcours cibles d'accès aux données
Selon que les données seront identifiantes ou non, les parcours d'accès seront distincts.
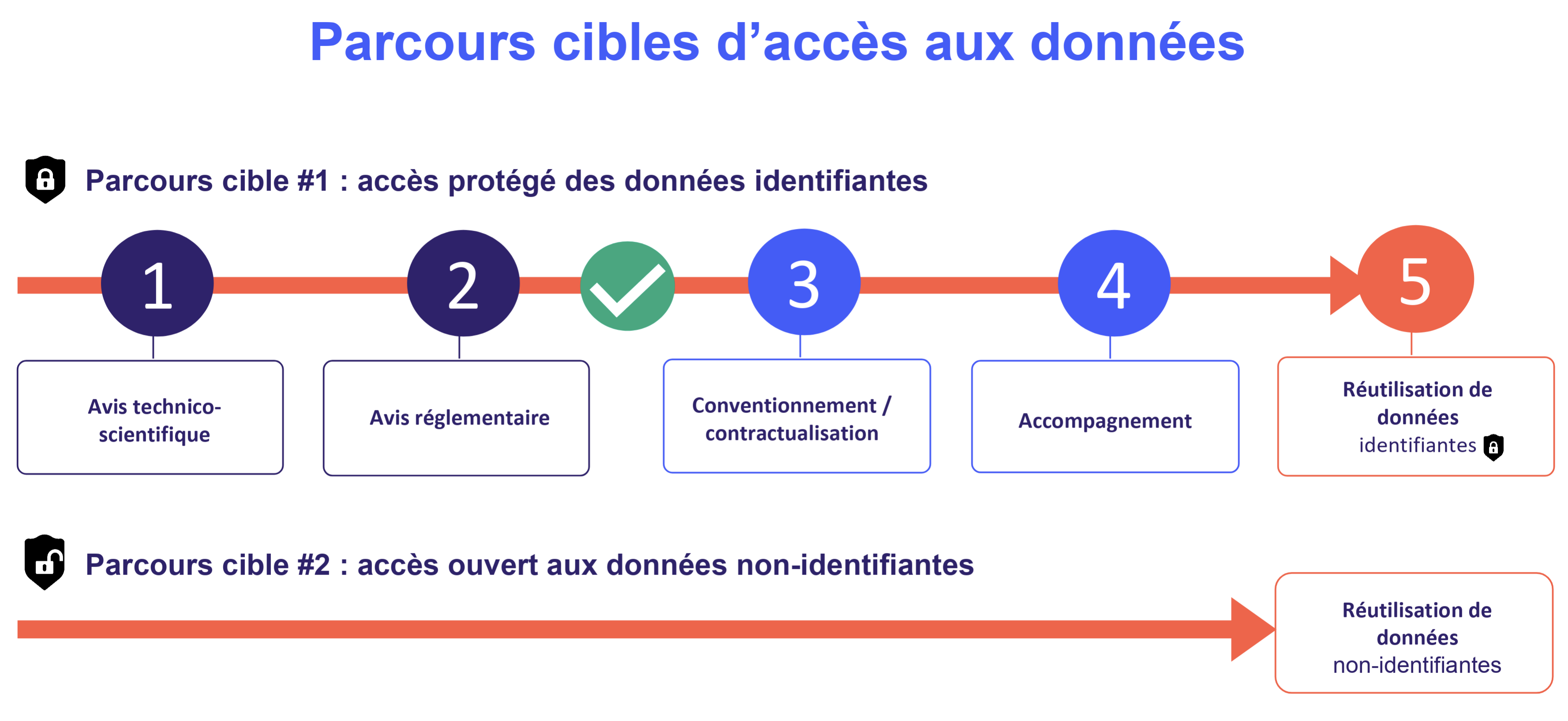
France Cohortes met à disposition les données des cohortes sur une plateforme informatique sécurisée et conforme à la réglementation en vigueur, permettant à chaque chercheuse ou chercheur habilité(e) de se créer un espace individuel de gestion de données.
Actuellement, seules les cohortes inscrites dans la feuille de route 2021-2024 de France Cohortes peuvent y accéder. La plateforme sera progressivement ouverte à d’autres projets de recherche à l'issue de cette période. Nous contacter pour plus d’informations.
La documentation associée aux données de recherche
Partager des données de santé pour une utilisation différente de ce pour quoi elles étaient destinées au départ nécessite de leur associer une documentation accessible, compréhensible et complète.
En effet, le recueil et/ou l’interprétation de la donnée évoluent dans le temps. Les données sont recueillies en fonction d’un savoir, d’une législation, ou encore de contraintes extérieures qui peuvent changer.
La construction d’une documentation qui accompagne tout le cycle de vie de la donnée constitue dès lors un enjeu de qualité bien connu des épidémiologistes, surtout pour les données de recueil longitudinal.
Le choix des standards de données et de métadonnées
Il existe de nombreux standards de données et de métadonnées dans le domaine de la biologie-santé :
- Les standards de communication médicaux : HL7-FHIR, DICOM
- Les standards de structuration des données et de vocabulaire contrôlé en recherche clinique : CDISC/SDTM, CDISC/ADAM, OMOP
- Les standards de terminologie : CIM 10 pour les maladies ; SNOMED pour les activités cliniques ; LOINC pour les médicaments, les actes cliniques ou biologiques ; Orphanet pour les maladies rares
- Les référentiels géographiques hébergés par les sites de référence : pays, communes, hôpitaux
- Les standards de métadonnées : DDI, DCAT-AP, Data Cite
- etc.
Focus : un exemple de catalogue de terminologies
L’Agence du numérique en santé (ANS) a développé et mis à disposition un serveur multiterminologique en santé (SMT) pour favoriser et encourager l’interopérabilité entre les systèmes d’information en santé. Il est régulièrement enrichi, historisé, mis en correspondance et à jour. France Cohortes souhaite mettre ce serveur à disposition des cohortes dans son système d’information.
Cela peut néanmoins être difficile pour les cohortes d'identifier les standards les plus adaptés.
C'est pourquoi France Cohortes souhaite accompagner la communauté à se structurer sur ces sujets. De manière collective, il s'agit d'identifier les standards et de partager des outils d'aides à la standardisation des données et des métadonnées.
Focus : co-construire la standardisation au sein d'un groupe de travail FAIR
France cohortes anime un groupe de travail FAIR avec des cohortes volontaires associées à la feuille de route de l’infrastructure. Ce groupe échange autour de bonnes pratiques visant à renforcer leur stratégie FAIR Data et contribue à la structuration des outils mutualisés.
Le prochain atelier portera sur les standards de métadonnées (DDI, DCAT, etc.). Si vous souhaitez participer au groupe de travail FAIR, merci de nous contacter.
Les 2 grandes étapes de FAIRisation des données
La phase amont du recueil de données
Idéalement, l’étape de structuration et du choix des standards de données, des métadonnées et du vocabulaire doit être définie dès la phase amont du recueil des données.
C’est ce qu’on pourrait appeler le « FAIR à chaud »[6]. Les données et les métadonnées associées sont alors enrichies sous des formats standards tout au long du cycle de vie de la donnée, jusqu’à sa consolidation définitive.
La phase avale du catalogage des données
Le renseignement des métadonnées peut aussi se faire lors du catalogage des données, une fois que ces dernières ont été recueillies, traitées et consolidées. Il s’agit alors d’une étape de « FAIR à froid » [6], avec une documentation manuelle des métadonnées. Dès lors, le travail à fournir par les datamanagers est important. Ce travail doit être envisagé pour les données anciennes.
Focus : le catalogue de cohortes et de métadonnées
Un catalogue de cohortes et de données est actuellement en cours de développement au sein de France Cohortes.
En attendant, pour accéder aux données des cohortes, nous vous invitons à les contacter individuellement : cliquer ici pour accéder à la liste des cohortes.
Le rôle d’accompagnement de France Cohortes
En définitive, les cohortes perçoivent bien les enjeux associés aux données FAIR : la pérennité, la qualité des données, et la visibilité de leurs travaux.
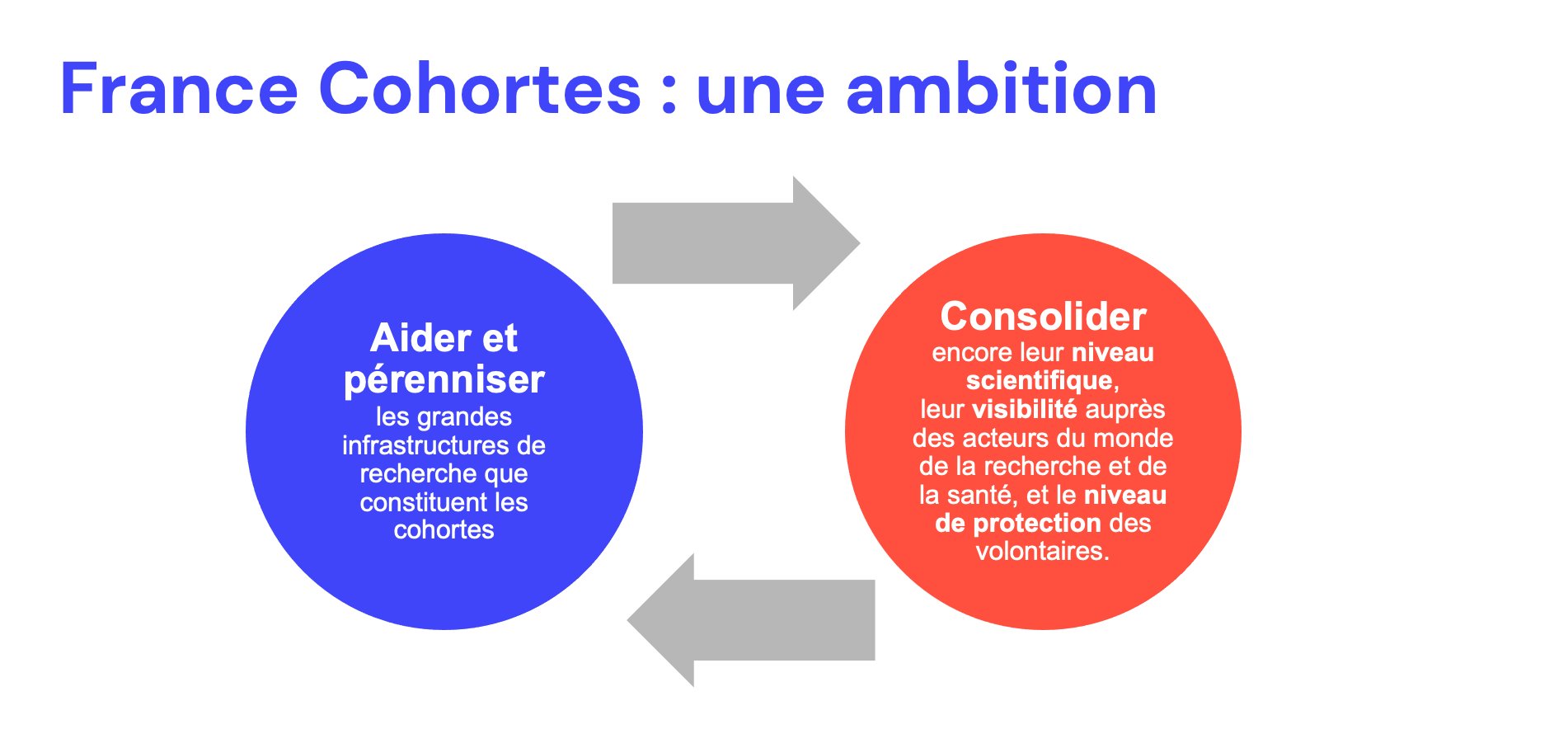
La politique de FAIRisation des données varie selon si les cohortes existent déjà ou sont en cours de création.
Les cohortes déjà constituées recherchent d’abord un outil qui puissent diffuser leur catalogue et leurs processus d’accès aux données (FAIR « à froid »). Par la suite, France Cohortes pourra les accompagner en amont du cycle de vie de la données (FAIR « à chaud »).
Instaurer une démarche FAIR sur les projets est en effet un processus à réaliser étape par étape, jusqu’à ce que cela devienne in fine une bonne pratique totalement intégrée au champ de recherche.
Les cohortes en cours de création intègrent en revanche les processus FAIR dès le début du projet (« à chaud »), au moyen d’un plan de gestion des données et de l’enrichissement automatisé des métadonnées lors de la phase d’élaboration du questionnaire.
La priorité actuelle de France Cohortes consiste dès lors à développer, de manière concertée, un outil centralisant et facilitant la documentation et les métadonnées tout au long de la vie de l’étude de cohorte.
Auteures : Claire Imbaud, Guillemette Pardoux de France Cohortes.
Remerciements : Lesya Baudoin de l'Institut de santé publique de l'Inserm, Julie Hubert et Grégoire Rey de France Cohortes, Yvan Le Bras du Museum national d'histoire naturelle (MNHN), l'initiative CLOSER en Grande Bretagne, Doranum, la Banque nationale de données des maladies rares (BNDMR), l'Institut français de bioinformatique (IFB).
-------
Notes :
[1] L’accès et l’utilisation des données sont encadrées par :
Le règlement général sur la protection des données RGPD — règlement UE 2016/679 du Parlement européen et du Conseil du 27 avril 2016), qui encadre le traitement des données pour protéger les citoyens sur l’ensemble du territoire de l’Union européenne,
Les dispositions sur le secret (art. L. 1110-4 du Code de Santé Publique - CSP), impliquant que toute personne entrant dans le système de santé a droit au respect de sa vie privée et du secret des informations la concernant.
[2] La loi française « pour une république numérique » (loi n° 2016-1321 du 7 octobre 2016) travaille à ouvrir les données tout en renforçant la protection des personnes.
[3] Par exemple, les métadonnées peuvent être :
- les informations générales sur la cohorte, les objectifs scientifiques, le nom des porteurs de projet et toutes les personnes/institutions associées, les dates de collecte, l’origine des données,
- des données agrégées descriptives non ré-identifiantes,
- la liste des variables et les informations associées,
- des éléments plus spécifiques : test de cohérence, conditionnement des réponses, type de nettoyage effectué, principales modifications entre vague de collecte, etc.
[4] Le texte de loi encadrant le consentement éclairé des volontaires :
L’article1 L.1122-1-1 du code de la santé publique déclare qu’« aucune recherche biomédicale ne peut être pratiquée sur une personne sans son consentement libre et éclairé, recueilli après que lui a été délivrée l'information prévue ».